
概述
Kafka端到端审计是指生产者生产的消息存入至broker,以及消费者从broker中消费消息这个过程之间消息个数及延迟的审计,以此可以检测是否有数据丢失,是否有数据重复以及端到端的延迟等。
目前主要调研了3个产品:
- Chaperone (Uber)
- Confluent Control Center(非开源,收费)
- Kafka Monitor (LinkedIn)
对于Kafka端到端的审计主要通过: - 消息payload中内嵌时间戳timestamp
- 消息payload中内嵌全局index
- 消息payload中内嵌timestamp和index
内嵌timestamp的方式
主要是通过设置一个审计的时间间隔(这里称之为time_bucket_interval,可以设置几秒或者几分钟,这个可以自定义), 每个timestamp都会被分配到相应的桶中,算法有:
- timestamp - timestamp%time_bucket_interval
- floor((timestamp /15)*15)
这样可以获得相应time_bucket的起始时间time_bucket_start,一个time_bucket的区间可以记录为[time_bucket_start, time_bucket_start+time_bucket_interval]。
每发送或者消费一条消息可以根据消息payload内嵌的时间戳,分配到相应桶中,然后对桶进行计数,之后进行存储,简单的可以存储到,比如:Map
内嵌index的方式
这种方式就更容易理解了,对于每条消息都分配一个全局唯一的index,如果topic及相应的partition固定的话,可以为每一个topic-partition设置一个全局的index,当有消息发送到某个topic-partition中,那么首先获取其topic-partition对应的index, 然后内嵌到payload中,之后再发送到broker。消费者进行消费审计,可以判断出哪个消息丢失,哪个消息重复等等。如果要计算端到端延迟的话,还需要在payload中内嵌timestamp以作相应的计算。
下面来简要分析下三个产品。
Chaperone
- github地址:https://github.com/uber/chaperone
- 官方介绍(中文):http://www.infoq.com/cn/news/2016/12/Uber-Chaperone-Kafka
- 官方介绍(英文):https://eng.uber.com/chaperone/
Chaperone进行消息端到端的校验主要是基于message内置timestamp实现的,根据timestamp将message分配到不同的bucket中。之后就是对这个bucket中的消息进行计数等一系列的audit操作,然后将这个audit操作之后的信息auditMessage保存起来,auditMessage的内容:
- topicName:被audit的topic
- time_bucket_start:bucket的起始时间
- time_bucket_end
- metrics_count:time_bucket中的个数
- metrics_mean_latency, metrics_p95_latency, metrics_p99_latency,metrics_max_latency:延迟
- tier
- hostname
- datacenter
- uuid
注意: 这里的latency的计算规则是:currentTimeMillis - (timestamp*1000)。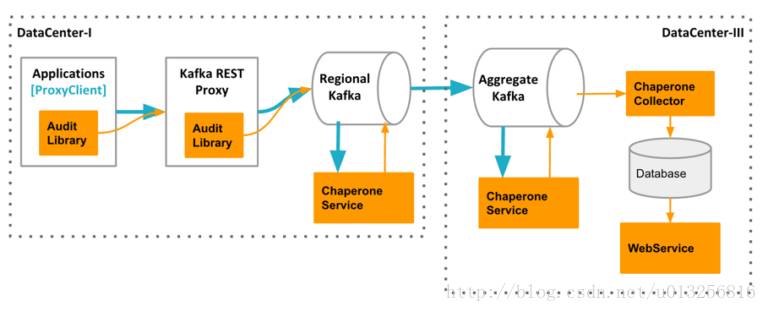
Chaperone的架构
Chaperone的整体架构分为:AuditLibrary, ChaperoneService, ChaperoneCollector和WebService, 它们会收集数据,并进行相关计算,自动检测出丢失和延迟的数据,并展示审计结果。
从Chaperone的github上的源码来看:
Chaperone分为ChaperoneClient, ChaperoneCollector, ChaperoneDistribution, ChaperoneServiceController, ChaperoneServiceWorker这5个子项目。对比着上面的架构图来分析。
- ChaperoneClient对应着AuditLibrary,主要是用来audit message的库(library),并不以实际服务运行,可以在Producer或者Consumer客户端中调用,默认使用10mins的滚动时间bucket来不断地从每个主题收集消息。然后发送到kafka的chaperone-audit这个topic中。官方文档介绍说AuditLibrary会被ChaperoneService, ChaperoneCollector和WebService这三个组件所依赖,但代码中来看并非完全如此,略有出入。
- ChaperoneDistribution可以忽略
- ChaperoneServiceController和ChaperoneServiceWorker对应架构图中的ChaperoneService,ChaperoneServiceController主要用来检测topics并分配topic-partitions给ChaperoneServiceWorker用以审计(audit)。ChaperoneServiceWorker主要是audit message的一个服务。
- ChaperoneServiceWorker采用scala语言编写,内部又将ChaperoneClient或者说AuditLibrary又重新用Scala实现了一番,并丰富了一下应用,比如采用hsqldb存储数据,zk存取offsets来实现WAL(预写式日志,具体可见下段介绍)
- Chaperone认为message中内嵌timestamp是十分必须的,但是从ChaperoneServiceWorker的代码来看消息没有timestamp也能运行,当消息没有时间戳,那么会记录noTimeMsgCount,Chaperone介绍会有一个牛逼的算法来分析消息中的timestamp(其实就是读取消息的开头部分,而不是全部整条消息,类似报文截断解析,下面也有涉及介绍),如果解析timestamp失败,会记录malformedMsgCount。
- ChaperoneCollector对是用来读取audit的数据,然后持久化操作,默认存入mysql中,看代码也可选存入redis中。
- 源码中没有WebService这个东西,估计是uber内部的web系统,读取下mysql中的内容展示到页面而已。
如果程序段内嵌Audit Library(ChaperoneClient),那么整个audit过程如下: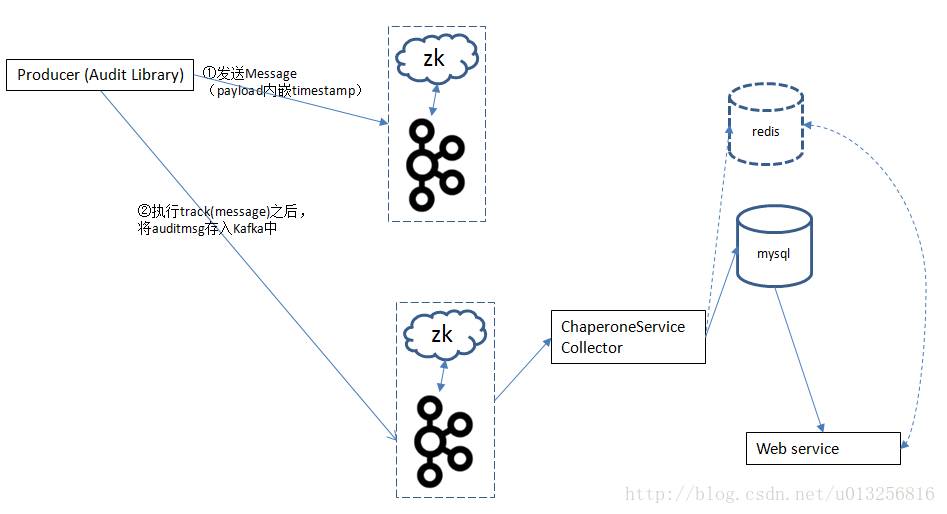
如果producer端或者consumer端需要进行消息审计,那么可以内嵌Audit Library。就以发送端为例,消息先发送到kafka中,然后对这条消息进行审计,将审计的信息存入到kafka中,之后有专门的ChaperoneServiceCollector进行数据消费,之后存入mysql中,也可以选择存入redis中。页面系统webService可以查询mysql(redis)中的数据,之后进而在页面中展示。
如果使用ChanperoneServiceWork,整个流转过程如下: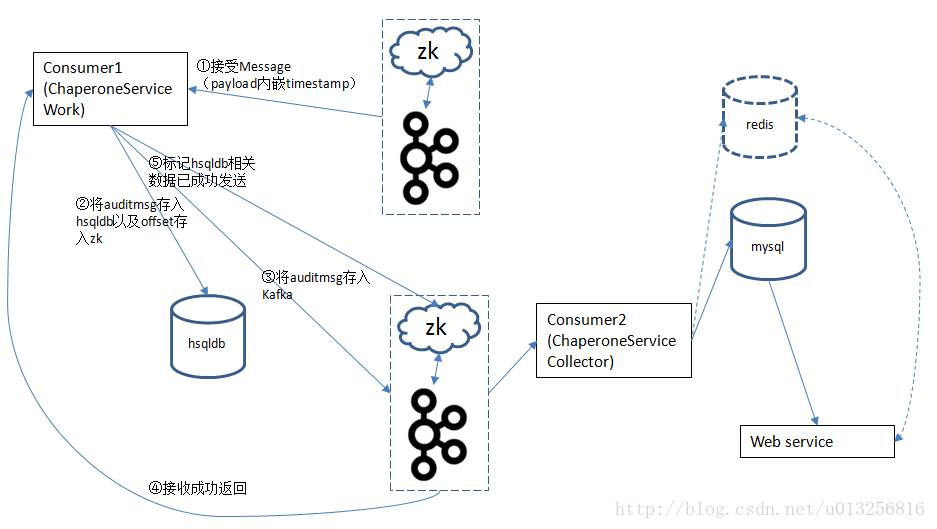
上面是对broker端进行审计的过程。首先从存储消息的kafka(图中上面的kafka)中消费数据,之后对收到的消息进行审计操作,之后将审计消息auditmsg以及相应的offset存储起来(auditmsg存入hsqldb中,offset存到用来存储审计数据的kafka的zk之中),之后再将审计消息auditmsg存入kafka(图中下面的kafka)中,最后成功存储并返回给消费端(Consumer1,即ChaperoneServiceWork),之后再把hsqldb中的auditmsg标记为已统计。之后ChaperoneServiceCollector和producer端(consumer端)内嵌Audit Library时相同。
官方文档部分介绍如下:
每个消息只被审计一次
为了确保每个消息只被审计一次,ChaperoneService使用了预写式日志(WAL)。ChaperoneService每次在触发Kafka审计消息时,会往审计消息里添加一个UUID。这个带有相关偏移量的消息在发送到Kafka之前被保存在WAL里。在得到Kafka的确认之后,WAL里的消息被标记为已完成。如果ChaperoneService崩溃,在重启后它可以重新发送WAL里未被标记的审计消息,并定位到最近一次的审计偏移量,然后继续消费。WAL确保了每个Kafka消息只被审计一次,而且每个审计消息至少会被发送一次。
接下来,ChaperoneCollector使用ChaperoneService之前添加过的UUID来移除重复消息。有了UUID和WAL,我们可以确保审计的一次性。在代理客户端和服务器端难以实现一次性保证,因为这样会给它们带来额外的开销。我们依赖它们的优雅关闭操作,这样它们的状态才会被冲刷出去。
在层间使用一致性的时间戳
因为Chaperone可以在多个层里看到相同的Kafka消息,所以为消息内嵌时间戳是很有必要的。如果没有这些时间戳,在计数时会发生时间错位。在Uber,大部分发送到Kafka的数据要么使用avro风格的schema编码,要么使用JSON格式。对于使用schema编码的消息,可以直接获取时间戳。而对于JSON格式的消息,需要对JSON数据进行解码才能拿到时间戳。为了加快这个过程,我们实现了一个基于流的JSON消息解析器,这个解析器无需预先解码整个消息就可以扫描到时间戳。这个解析器用在ChaperoneService里是很高效的,不过对代理客户端和服务器来说仍然需要付出很高代价。所以在这两个层里,我们使用的是消息的处理时间戳。因为时间戳的不一致造成的层间计数差异可能会触发错误的数据丢失警告。我们正在着手解决时间戳不一致问题,之后也会把解决方案公布出来。
温馨提示: github上的quickstart中,如果不能根据脚本自动安装kafka和zk,而是自己安装kafka和zk的话,需要改动脚本、配置文件甚至源码才能将服务运行起来。另外需要安装hsqldb和mysql(redis)。
Confluent Control Center
文档地址:http://docs.confluent.io/3.0.0/control-center/docs/index.html
这是个收费产品,文档中介绍的并不多。和Chaperone相同,主要也是根据消息payload内嵌timestamp来实现,计算time_bucket的算法是:floor((timestamp /15)*15)。
架构图如下: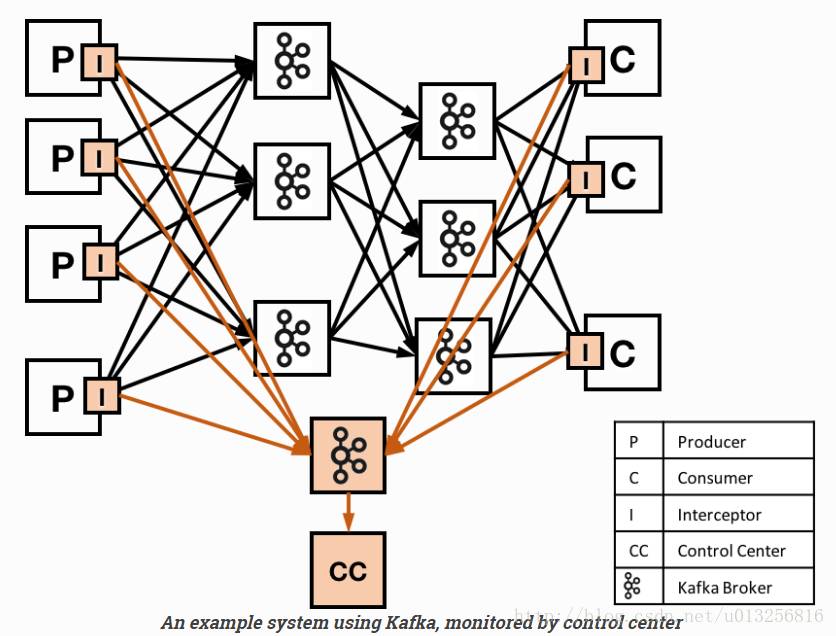
主要是在producer端或者consumer端内嵌审计程序(相当于Chaperone的Audit Library)继续审计,最终将审计消息同样存入kafka中,最后的web系统是直接消费kafka中的审计消息进行内容呈现。
web系统部分呈现如下: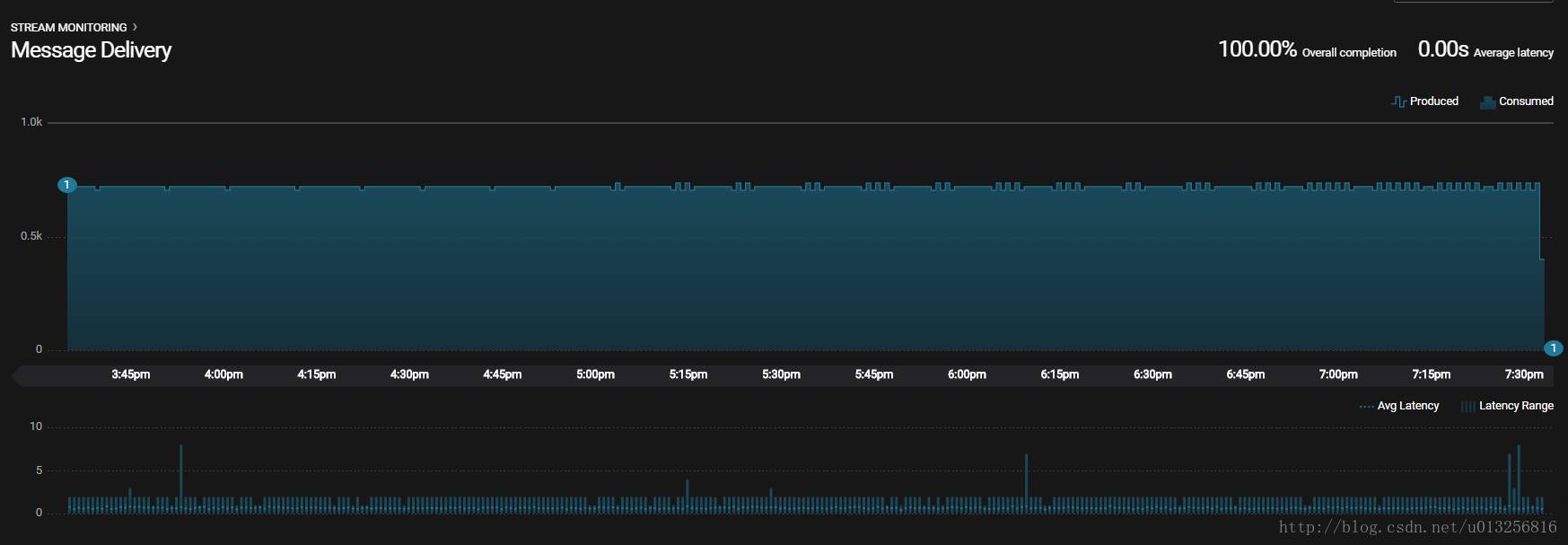
Kafka Monitor
github地址:https://github.com/linkedin/kafka-monitor
Kafka Monitor是基于在消息payload内嵌index和timestamp来实现审计:消息丢失,消息重复以及端到端延迟等。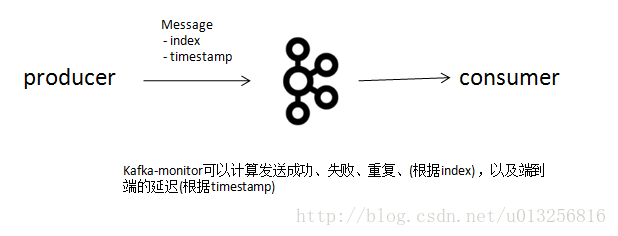
web系统部分呈现如下:
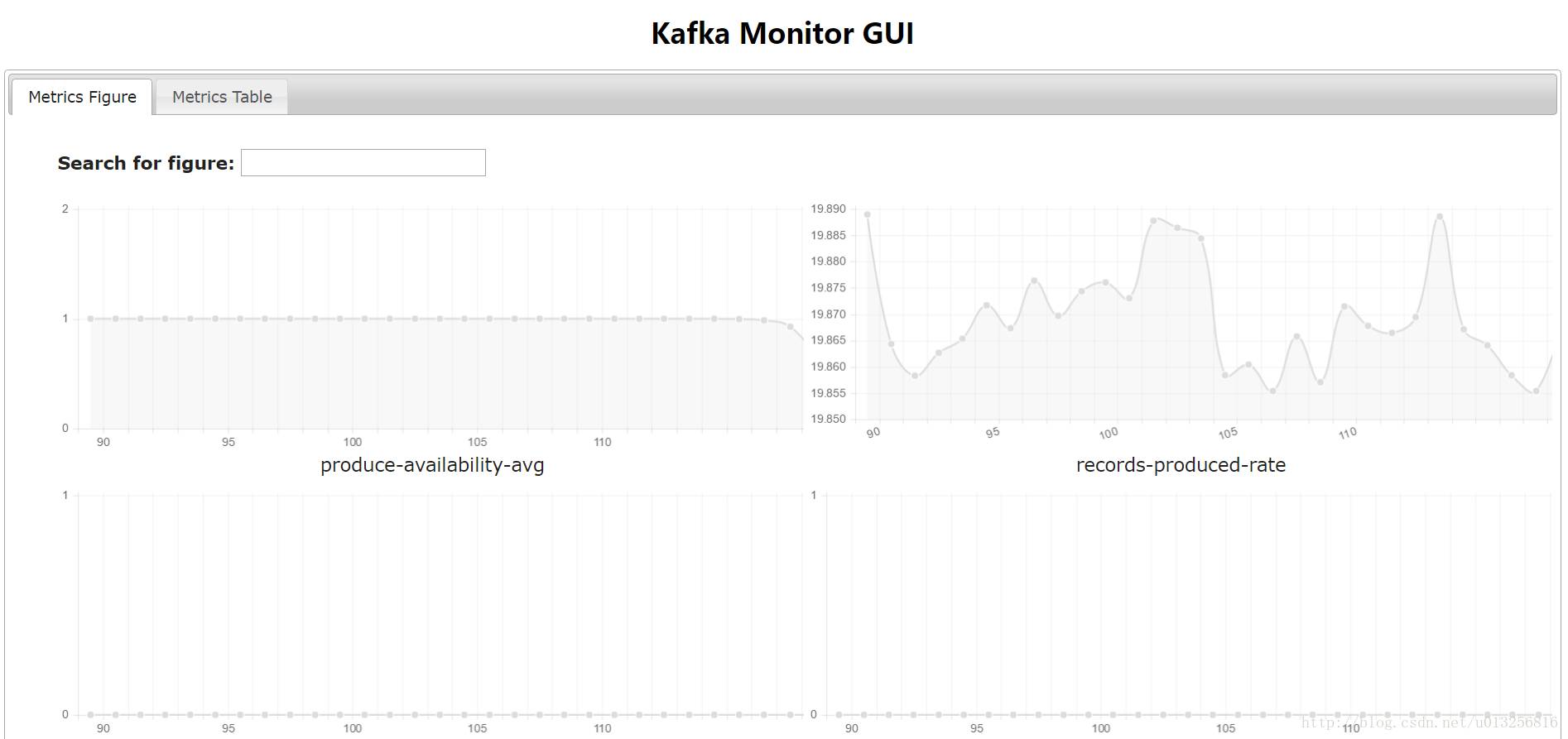
几种典型的metrics解释:
| name | description |
|---|---|
| produce-avaliablility-avg | The average produce availability |
| consume-avaliability-avg | The average consume availability |
| records-produced-total | The total number of records that are produced |
| records-consumed-total | The total number of records that are consumed |
| records-lost-total | The total number of records that are lost |
| records-duplicated-total | The total number of records that are duplicated |
| records-delay-ms-avg | The average latency of records from producer to consumer |
| records-produced-rate | The average number of records per second that are produced |
| produce-error-rate | The average number of errors per second |
| consume-error-rate | The average number of errors per second |
| records-delay-ms-99th | The 99th percentile latency of records from producer to consu |
| records-delay-ms-999th | The 999th percentile latency of records from producer to consumer |
| records-delay-ms-max | The maximum latency of records from producer to consumer |